03. Course Outline, Case Studies
Course Outline
Throughout this course, we’ll be focusing on deployment tools and the machine learning workflow; answering a few big questions along the way:
- How do you decide on the correct machine learning algorithm for a given task?
- How can we utilize cloud ML services in SageMaker to work with interesting datasets or improve our algorithms?
To approach these questions, we’ll go over a number of real-world case studies , and go from task and problem formulation to deploying models in SageMaker. We’ll also utilize a number of SageMaker’s built-in algorithms.
Case Studies
Case studies are in-depth examinations of specific, real-world tasks. In our case, we’ll focus on three different problems and look at how they can be solved using various machine learning strategies. The case studies are as follows:
Case Study 1 - Population Segmentation using SageMaker
You’ll look at a portion of US census data and, using a combination of unsupervised learning methods, extract meaningful components from that data and group regions by similar census-recorded characteristics. This case study will be a deep dive into Principal Components Analysis (PCA) and K-Means clustering methods, and the end result will be groupings that are used to inform things like localized marketing campaigns and voter campaign strategies.
Case Study 2 - Detecting Credit Card Fraud
This case will demonstrate how to use supervised learning techniques, specifically SageMaker’s
LinearLearner
, for fraud detection. The payment transaction dataset we'll work with is unbalanced, with many more examples of valid transactions vs. fraudulent, and so you will investigate methods for compensating for this imbalance and tuning your model to improve its performance according to a specific product goal.
Custom Models - Non-Linear Classification
Adding on to what you have learned in the credit card fraud case study, you will learn how to manage cases where classes of data are not separable by a linear line. You'll train and deploy a custom, PyTorch neural network for classifying data.
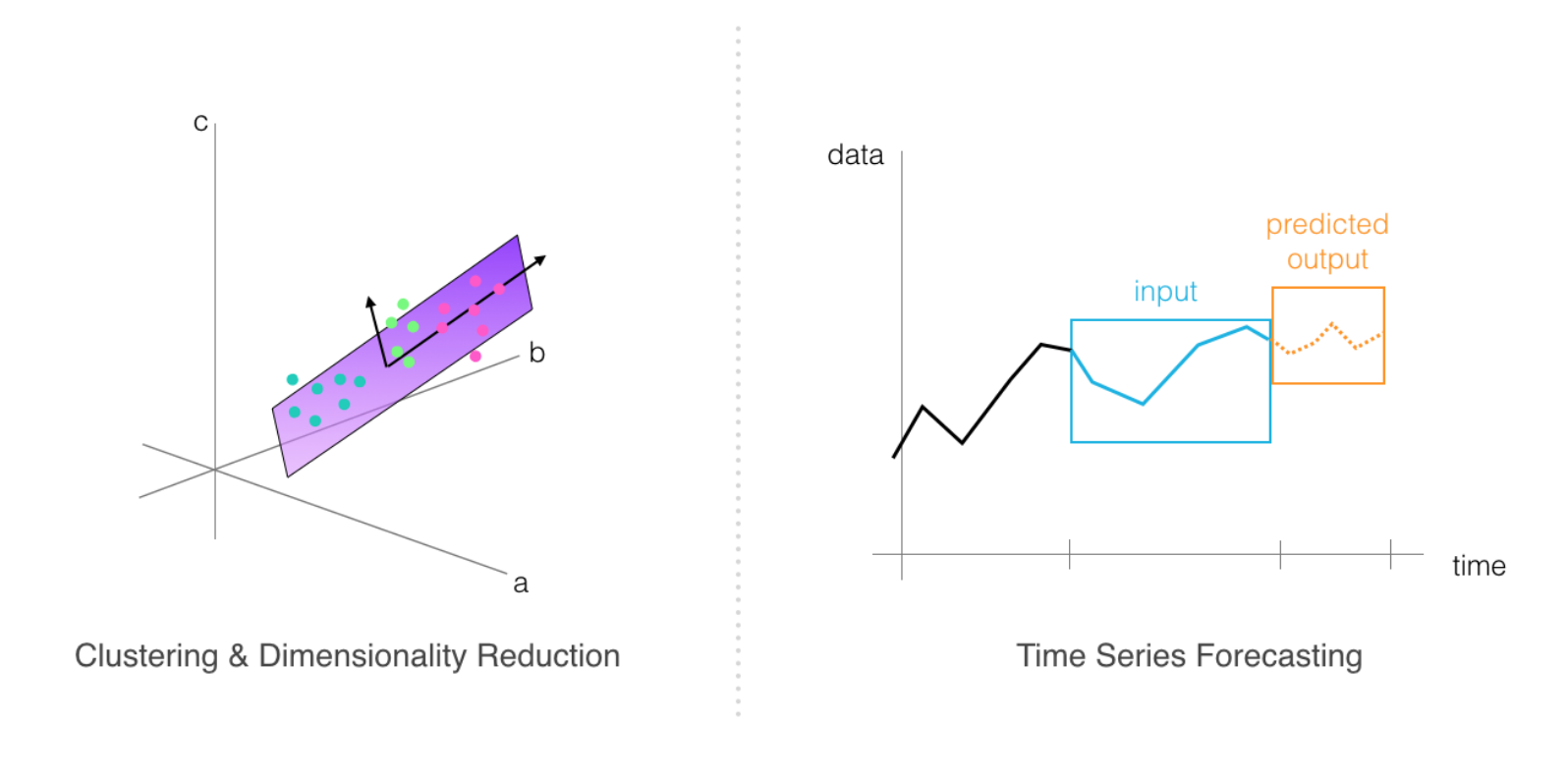
Case Study 3 - Time-Series Forecasting
This case demonstrates how to train SageMaker's DeepAR model for forecasting predictions over time. Time-series forecasting is an active area of research because a good forecasting algorithm often takes in a number of different features and accounts for seasonal or repetitive patterns. In this study, you will learn a bit about creating features out of time series data and formatting it for training.
Project: Plagiarism Detection
You'll apply the skills that you've learned to a final project; building and deploying a plagiarism classification model. This project will test your ability to do [text] data processing and feature extraction, your ability to train and evaluate models according to an accuracy specification, and your ability to deploy a trained model to an endpoint.
By the end of this course, you should have all the skills you need to build, train and deploy models to solve tasks of your own design!